
今回は世界的な画像認識コンペであるISLVRCで2014年に準優勝を飾ったVGGを紹介してみようと思います。
画像認識CNNの火付け役となったAlexNetとの比較も交えて紹介していこうと思いますので、AlexNetをご存知ない方は是非↓の記事をまず読んでみて下さい。

VGGとは?
VGGはオックスフォード大学のVisual Geometry Groupによって開発されたモデルです。お察しの通り、ネーミングはグループ名の頭文字に由来します。
VGGもAlexNetと同様に畳み込み層、プーリング層、全結合層を持っています。
まずは、これらの層がどのような構造になっているのかを見ていきましょう。
224×224のサイズ(RGBの3チャンネル)の入力画像に対して、3×3のサイズで64枚のフィルターを適用して、畳み込みを行ないます。AlexNetでは11×11、5×5、3×3などのフィルターが使われていましたが、VGGにおけるフィルターは3×3しかありません。
stride=1・padding=1という条件なので、畳み込み後もサイズの変化はなく、224×224です。
畳み込み後のサイズ計算が分からない方は、【初心者でも分かる】畳み込みニューラルネットワークを基礎から解説をご参照ください。
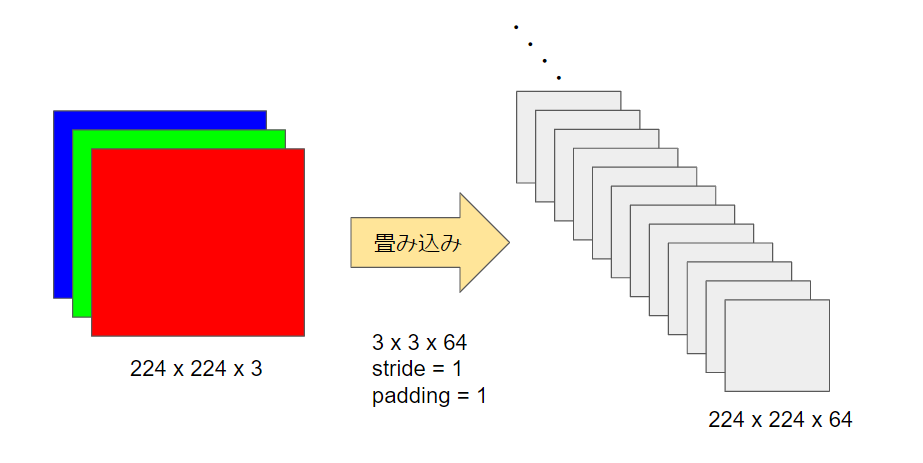
畳み込みの後の活性化関数は、AlexNetと同じく、ReLUを使っています。ReLu関数が分からない方は是非↓の記事も読んでみて下さい。

VGGでは、最初と同様に、ここで3×3のフィルターをもう1度適用します。同じ操作なので、ここでも出力サイズは224×224のままです。
ここで初めて、サイズ変更をするために最大値プーリングを行ないます。2×2のプーリングをstride=2の条件で行ないます。そのため、出力サイズはちょうど半分(112×112)になります。
プーリング後のサイズ計算が分からない方は、【初心者でも分かる】畳み込みニューラルネットワークを基礎から解説をご参照ください。
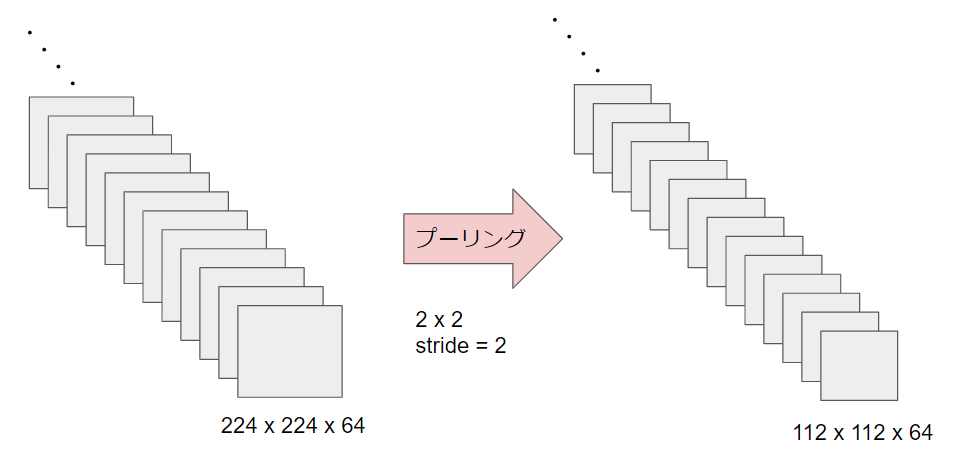
ここまで見たように、VGGは3×3のフィルターを数回通して、その後に最大値プーリングでサイズを半分にするということを繰り返します。
では、何回繰り返すのかというと、それはモデルによります。ここまでVGGと一口に言ってきましたが、VGG16やVGG19など層の深さによっていくつかのモデルが存在します。例えば、VGG16であれば、畳み込み層13層+全結合層3層という構成になっています。
VGG16の場合の構造を示すと以下のようになります。
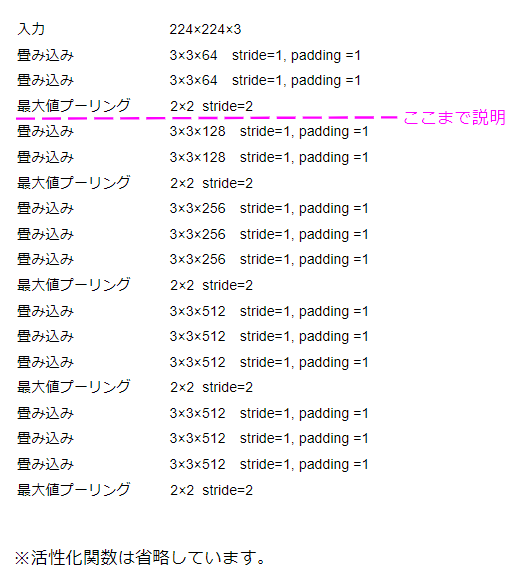
この図から分かるように、畳み込み層を全て通った時点で最大値プーリングを5回実行しているので、入力画像のサイズは
$224 × \frac{1}{2} × \frac{1}{2} × \frac{1}{2} × \frac{1}{2} × \frac{1}{2} = 7$
つまり、7×7になっています。
さて、最後は全結合層です。
7×7の出力が512枚(フィルターの数)ありますから、これを全結合層で1列に直すと、$7 × 7 × 512 = 25088$個のノードがあることになります。
それも踏まえると、VGGの全結合層は次のようになります。端的に言ってしまえば、AlexNetと同じです。
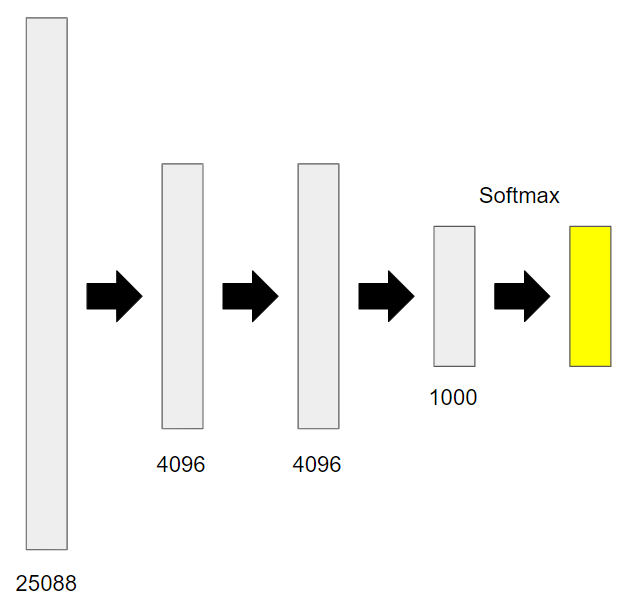
ILSVRCでは1000クラスの画像分類を行なうことが目的なので、最後はノード数が1000個になっています。
1000クラスの画像分類を行なうということは、各クラスに該当する確率を計算するので、最後はsoftmax関数を使って確率に変換しています。
※softmax関数って何?という方は↓の記事でご確認ください。

VGGの特長
ここまでVGGの構造について説明してきました。
VGGはISLVRCにおいてAlexNetよりも画像認識のエラー率が低く、優秀なモデルだと認識されています。
では、どういった点が具体的に優れているのでしょうか?
①パラメータ数が少なく済む
VGGではAlexNetより層が深くなっており、畳み込みのフィルターの数が多いので、一見するとVGGの方がパラメータ数が多くなりそうな気がします。
もし、フィルターのサイズが全く同じであれば、フィルターの数が多い方がパラメータ数は多くなります。しかしながら、VGGはフィルターサイズが3×3と小さいものしかありません。一方のAlexNetは11×11のように大きなサイズのフィルターも含んでいます。
実は同じ畳み込みを行なうのであれば、大きいフィルターで1度に実行するよりも小さいフィルターを複数重ねる方が結果的にパラメータ数は小さくなります。
言葉だけでは分かりづらいと思うので例を示します。
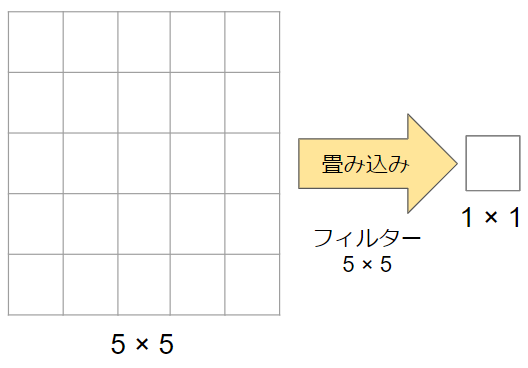
以下の図では、5×5の画像に5×5のフィルターを適用しています。適用後の画像サイズは1×1です。5×5のフィルターを使用しているので、パラメータの数は5×5=25個です。
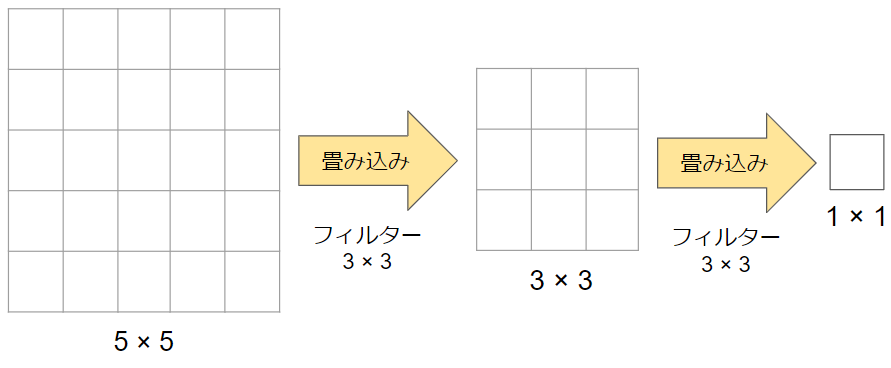
一方、こちらの図は5×5の画像に3×3のフィルターを2回適用しています。適用後の画像サイズは先ほどと同様に1×1です。ただし、今回は3×3のフィルターが2つある状態なのでパラメータの数は3×3×2=18個です。
得られる結果は同じですが、パラメータの数が減少していることが分かると思います。
これがVGGの特長の1つです。
②多層化による表現力の向上
ニューラルネットワークはある程度までであれば、層を深くしていく方が画像認識などの識別精度は向上していきます。
(深過ぎると勾配消失問題が発生するので程度問題ではあります)
VGGの構造をAlexNetと比較してみれば分かりますが、VGGの方が層が多く深い構造を持っています。ただ単に層を深くすれば、パラメータが増えるなどのデメリットも発生しますが、先に述べたようにVGGでは結果的にパラメータが少なく済んでいるためデメリットは発生していません。
このような経緯から、VGGではAlexNetより精度が向上したと考えられています。
以上、簡単ですが、VGGを紹介させていただきました!!
本格的にAIを学ぶならキカガク長期コース
本記事では、基礎的な内容について解説を行ないましたが、より本格的にAIを学んでみたいという方にはキカガク長期コースの受講をお薦めします。
- 基礎理論からAI搭載のWEBアプリ開発まで幅広く学習可能
- 将来追加されるものも含めて、プロによる全ての講義動画がずっと見放題
- 質問し放題のチャットや定期的な個別メンタリングなどのサポート体制
- IT専門のキャリアアドバイザーによる転職サポート
- 中央省庁からの給付金対象であるため受講料が最大70%
- ディープラーニングE資格の受験資格を獲得可能
興味はあるけど、いきなり受講を申し込むには抵抗があるという方は、キカガク長期コースの無料オンライン説明会も是非活用してみてください!!










