
今回はISLVRC 2014の優勝モデルでGoogleが開発を行ったGoogleNetを取り上げてみたいと思います。
同じくISLVRC 2014に参加して準優勝だったVGGよりさらに層が深い構造になっているモデルです。前提としてVGGを把握しておくと理解しやすくなると思うので、VGGをご存知ない方は、まず↓の記事から読んでみてください。

GoogleNetの概要
まずはざっくりGoogleNetの全体像を眺めてみましょう。
Going deeper with convolutions
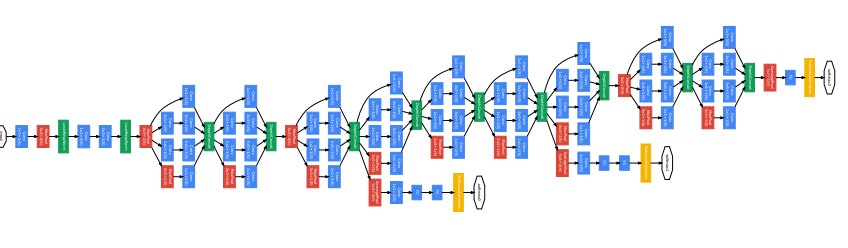
左から224×224の画像を入力し、それが畳み込みやプーリングを経て右に流れていきますが、まず注目するのは層の多さです。GoogleNetはAlexNet(5層)やVGG(13層)を上回る22層の構造です。
この層の深さによって、GoogleNetはILSVRCにおいてAlexNetやVGGを上回る性能を発揮したといっても過言ではありません。
しかし、ただ単に層を多くするだけでは、様々な問題が発生してしまうため、それらを回避しつつ層数を増やしたのがGoogleNetの素晴らしいところです。ここからはそんなGoogleNetの特長をいくつか紹介していきたいと思います。
Inceptionモジュール
GoogleNetでまず大きな特徴といえば、このinception(インセプション)モジュールです。
inceptionモジュールというのは以下の図に示すように、異なるサイズのフィルターを持つ畳み込み層の組み合わせで構成される層です。
Going deeper with convolutions
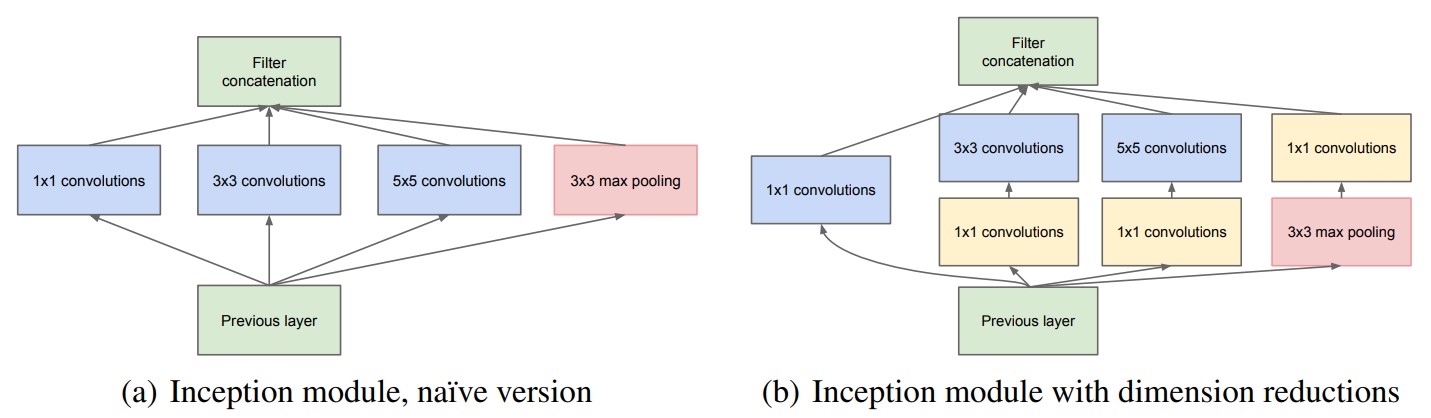
まず図の見方として、一番下の薄緑色の四角形が入力で、一番上の薄緑色の四角形が出力です。そして、それらの間にあるのが畳み込み層(一部プーリング層)です。”convolutions”というのが「畳み込み」という意味です。
ここで注目すべきは、1×1、3×3、5×5といった異なるサイズのフィルターが並列に置かれていることです。計算だけの話をするのであれば、これらの異なる畳み込みを経た画像が出力のところで連結されて、また次の層の入力になっていきます。
では、なぜこのように異なるサイズのフィルターを並列に置いた構造を採用しているのでしょうか?
まず前提として、異なるサイズのフィルターを用いるということは、様々な空間分解能で特徴抽出を行なえるということですから、1種類のフィルターしか使わないよりも性能的には有利になります。
しかしながら、畳み込み層を垂直にひたすら積み重ねていくと過学習や勾配消失問題が発生しやすくなることが知られています。そのため、単純に層を積み重ねるのは得策ではありません。
そのため、GoogleNetでは異なるサイズのフィルターを並列に置いたわけです。こうしておけば、層がどんどん積み重なることなく、フィルターの種類を増やすことができます。
pointwise convolution
ここまで読んできて、もしかすると1×1の畳み込みに疑問を持った方もいらっしゃるかもしれません。
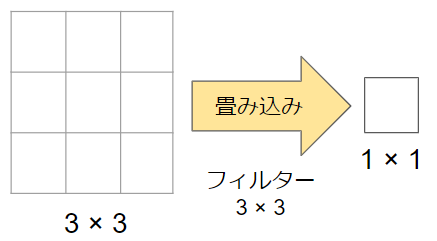
例えば、3×3の畳み込みであれば、以下の図にあるように、3×3の画素を1×1に集約することになります。一方、1×1のフィルターは適用しても画素サイズが変化するわけではありません。そういう意味では、一見あまり意味がなさそうに見えますが、このフィルターはどんな役割を担っているのでしょうか?
実はこの1×1の畳み込みを入れることによって大幅にパラメータの数を削減することができます。
実際に具体例を見てみましょう。
以下の2つのパターンについてパラメータ数を比較してみます。
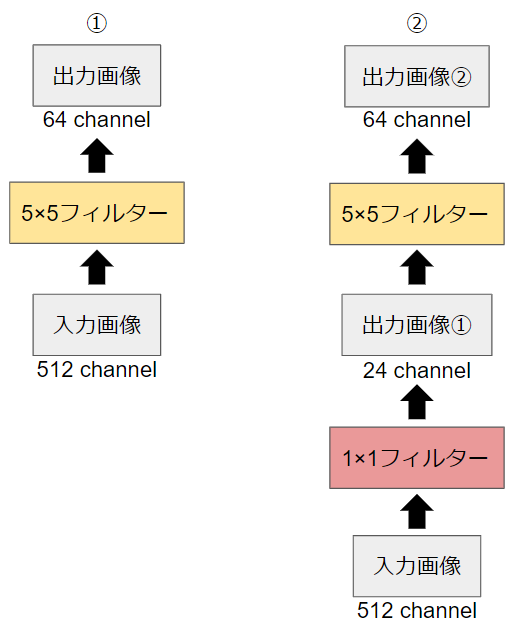
パラメータ数は(フィルター縦)×(フィルター横)×(入力画像チャンネル数)×(出力画像チャンネル数)で計算することができます。
パターン①の場合は$5×5×512×64 = 819200$です。
パターン②の場合は$(1×1×512×24) + (5×5×24×64) = 50688$です。
パラメータ数の差は歴然ですね。このように1×1のフィルターを入れることによって、パラメータ数を大きく削減しているのもinceptionモジュールの特長です。
ちなみに、このような1×1の畳み込みをpointwise convolution(ポイントワイズコンボリューション)と言います。
Auxiliary Loss
名称が難しいですが、「オーグジリアリーロス」と読みます。
これは一言でいえば、ニューラルネットワークの途中で損失関数を計算する仕組みです。
先ほど示したGoogleNetの全体構成の中からAuxiliary Lossに該当する箇所を切り取ってみます。
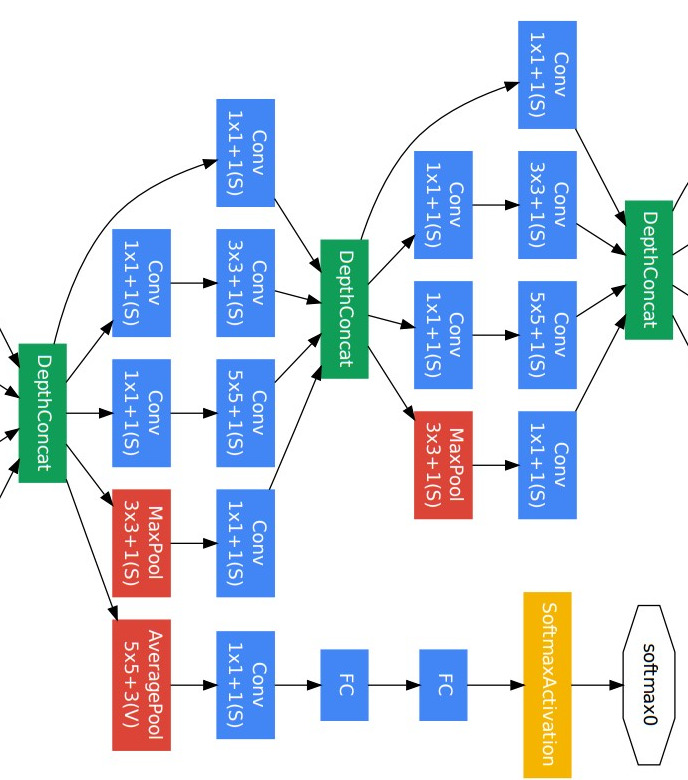
図の右下にsoftmax関数があるのが分るでしょうか?
GoogleNet全体としては、まだ先へ続いているのですが、この途中の段階でsoftmax関数に通して画像分類を行っています。ここで、いったん損失関数を計算するわけです。
では、なぜこのような操作を行うのでしょうか?
最初にも言ったように、GoogleNetはそれまでのCNNモデル比べて層が深いことが特徴です。そして、一般的に層が深いニューラルネットワークは勾配消失を起こしやすいという欠点があります。その欠点を補うために、浅い層からの損失関数も加味して学習を行うようにすることが狙いです。
※勾配消失が分らないという方は是非↓の記事をご一読ください。

また、途中で何度か画像分類を行うということは、画像分類を行うCNNモデルが複数あるのと同義です。このように複数のモデルを用いて行う学習をアンサンブル学習と言います。複数のモデルを使うということは、特定のモデルの結果に依存し過ぎないようにする効果があるので、過学習防止(正則化)につながるとも考えられます。
※アンサンブル学習を忘れてしまったという方は是非↓の記事もご参照ください。

Global Average Pooling
最後にご紹介するのはGlobal Average Poolingです。
これまで学んできたAlexNetやVGGは畳み込み層の後に、画像分類を行うための全結合層がありました。それはGoogleNetでも同じです。
ただし、GoogleNetでは畳み込み層から全結合層を作る際にGlobal Average Poolingという工夫を入れています。
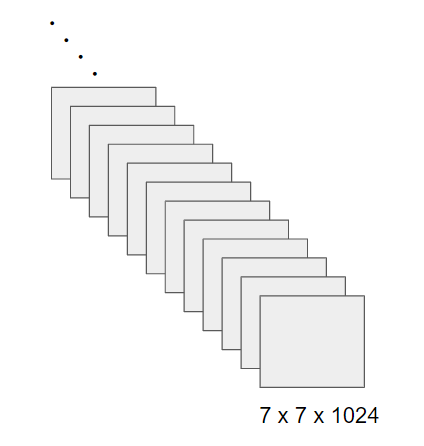
例えば、このように7×7の画像が1024チャンネルあるとします。
これまでの考え方で全結合層を作ると、ノードの数は$7×7×1024 = 50176$個になります。
Global Average Poolingでは、名前が示しているように、各チャンネルごとにプーリングを行って、サイズを1×1にしてしまいます。つまり、全結合層のノードの数は$1×1×1024 = 1024$個となります。
Global Average Poolingの効果としては、パラメータの数が削減されることによって、過学習防止につながることが知られています。
以上がGoogleNetの大きな特徴でした。
本格的にAIを学ぶならキカガク長期コース
本記事では、基礎的な内容について解説を行ないましたが、より本格的にAIを学んでみたいという方にはキカガク長期コースの受講をお薦めします。
- 基礎理論からAI搭載のWEBアプリ開発まで幅広く学習可能
- 将来追加されるものも含めて、プロによる全ての講義動画がずっと見放題
- 質問し放題のチャットや定期的な個別メンタリングなどのサポート体制
- IT専門のキャリアアドバイザーによる転職サポート
- 中央省庁からの給付金対象であるため受講料が最大70%
- ディープラーニングE資格の受験資格を獲得可能
興味はあるけど、いきなり受講を申し込むには抵抗があるという方は、キカガク長期コースの無料オンライン説明会も是非活用してみてください!!








