
今回は少し特殊なニューラルネットワークであるオートエンコーダー(自己符号化器)を取り上げてみたいと思います。
入力層・隠れ層・出力層の3層から成り、入力と出力が全く同じになるようなニューラルネットワーク
ニューラルネットワークであることは間違いありませんが、「入力と出力が全く同じ」というところが大きな特徴ですね。一見すると、あまり意味がないようにも見えるこのニューラルネットワークにどんな価値があるのかをここから解説していきます。
なお、ニューラルネットワークの基礎に自信がない方は是非↓の記事からお読みください。

オードエンコーダーとは?
オードエンコーダーの定義は冒頭で述べたように、入力層・隠れ層・出力層の3層を持ち、入力と出力が全く同じになるようなニューラルネットワークのことです。
ニューラルネットワークの構成を図で示すと以下のようになります。
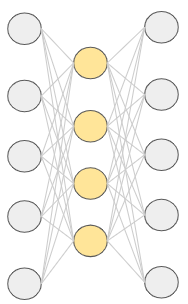
「入力と出力が全く同じ」ということは、例えば数字の「3」の画像を入力したら、それと全く同じ数字の「3」の画像が出力されるということです。
ニューラルネットワークと言えば、画像の分類を予測したりするようなものというイメージがあると思うので、そう考えるとこのオートエンコーダーは奇妙なものと感じるかもしれません。そもそも、入出力を全く同じにして何の意味があるのでしょうか?
オートエンコーダーの大きな特徴は次元削減だと言われています。先ほどのオートエンコーダーの構成図で隠れ層の次元(ノードの数)が入力層や出力層の次元より小さくなっていることに着目してください。
隠れ層の次元が小さいということは、入力層に入力された情報が隠れ層で圧縮されていることを意味します。ただし、オートエンコーダーは入力と全く同じものが出力層から出てくる仕組みですから、隠れ層の圧縮情報が入力と同じ状態に復元されることになります。
これは見方を変えれば、隠れ層で入力情報のエッセンスだけを抽出していると考えることができます。仮に隠れ層の情報圧縮で必要な情報が抜け落ちていれば、出力層で入力と同じものを再現できません。逆に言えば、それができているということは、入力情報の中から本質的に必要なものだけを抜き出しているということになります。
つまり、隠れ層では重要な情報を失うことなく、情報量を削減しているということになるので、次元削減と呼ばれるわけです。
膨大な情報を扱わなければならないディープラーニングにおいて、その負荷を少しでも軽減できる次元削減はとても重要な概念です。
ちなみに、次元を圧縮すること(入力層⇒隠れ層)をエンコード、次元を復元すること(隠れ層⇒出力層)をデコードといいます。
どうでしょう?
オートエンコーダーのすごさが伝わったでしょうか?
オートエンコーダの活用事例
ここではオートエンコーダーの活用事例を2つ紹介します。
異常検知
例えば、カメラで撮影した画像によって製品の不良判定をするような場合を考えてみて下さい。仮にカメラ撮影した映像に図形の〇が映っていれば良品、そうでなければ不良品(異常)だとします。
このような場合に、まずオートエンコーダを〇の画像を入力したら、〇の画像を出力するように訓練します。
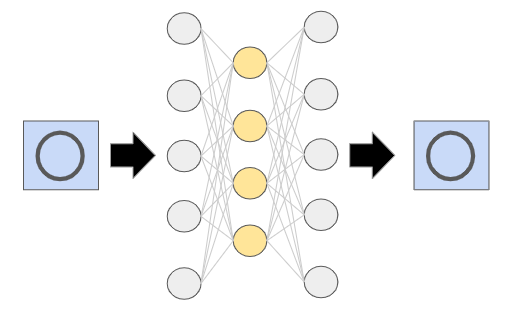
準備はこれだけです。実戦で使用した場合に、良品であれば〇の画像が入ってくるので、オートエンコーダーは〇の画像を出力します。しかし、不良品で○以外のが画像が入力された場合には、オートエンコーダーは〇の画像を出力できません。なぜなら、オートエンコーダーが学習したことのない画像が入力されてしまっているからです。
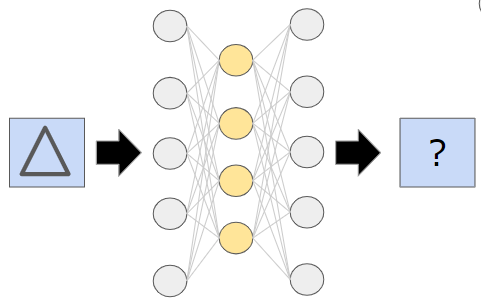
つまり、「オートエンコーダーの出力画像が○かどうか?」を見れば、良品・不良品の判定ができるということです。
ここで注目したいのは、学習においては異常画像を一切使用していないということです。
一般的に製品の検査などにおいて、不良品のサンプルというのは良品のサンプルに比べて得にくいものです。なぜなら、不良品が発生するのは稀だからです。ましてや、大量の不良品サンプルともなると準備が難しいので、それがないと学習できないようでは実用に耐えません。
そのような観点から良品のサンプルだけでよいオートエンコーダーは有用であると言えます。
ノイズ除去
これは例えば入力された画像の中からノイズ成分を取り除くのに使えます。ノイズ有り画像を入力データ、ノイズ無し画像を正解データとして、オートエンコーダーに教師あり学習をさせます。
学習後のオートエンコーダーにノイズ有り画像を入力すると、ノイズが除去された画像が出力されます。
積層オートエンコーダー
最後に積層オートエンコーダーを紹介します。
積層オートエンコーダーとは、その名の通り、オートエンコーダーを複数連ねたものですが、なぜこのようなものが必要になったのかの背景から説明していきます。
ニューラルネットワークには以前から勾配消失と呼ばれる大きな問題がありました。詳しくは是非↓の記事を読んでいただきたいですが、一言で言えば、ニューラルネットワークの層が深くなるにつれて勾配がほぼゼロになり、学習が進まなくなる現象でした。

この問題を解消するアプローチとして、ニューラルネットワークの層を分解して学習するという手段が考えられました。層が深いことが原因なのであれば、分解することで層を浅くして学習させればよいという発想ですね。
具体例として以下のようなニューラルネットワークがあるとします。
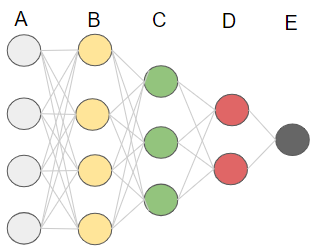
層を浅くするために、まずはニューラルネットワークの最初の所だけ取り出します。
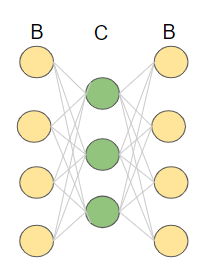
その際に、ただB層とC層を取り出すのではなく、上記のようにオートエンコーダーの形にして、これを学習させます。
ただし、学習すると言っても、分解した時点で本来とは違うニューラルネットワークになっているため厳密な学習をすることはできません。では、このオートエンコーダーで何を学習するのでしょうか?
答えは次元削減です。本来のニューラルネットワークに必要なパラーメータを学習することはできませんが、少なくともB層⇒C層と進んだ時に次元を減らしつつ情報を伝達するということは、分解前と分解後のニューラルネットワークで共通です。このような学習を行なうには、まさに最初に説明したオートエンコーダーの特性が適しているのです。これがオートエンコーダーが使われる理由です。
B層⇒C層の学習が終われば、その結果を使って以下のようにC層⇒D層の学習を行ないます。
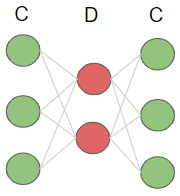
このようにして、オートエンコーダーを複数回適応して次々と学習を行なっていくものを積層オートエンコーダーと呼んでいます。
先ほど繰り返し言っているように、この積層オートエンコーダーによる学習はあくまで本来のニューラルネットワークの学習の前に行なう準備なので、事前学習と言われます。この事前学習をやっておくことによって、重みなどのパラメータがある程度調整されるので、本番の学習もやりやすくなるというメリットがあります。
今回は以上となります。
最後になりますが、より詳しく学んでみたいという方は、AIの基礎からAI搭載WEBアプリ開発まで学べるキカガク長期コースも活用してみてください!










