
今回はk-means法やウォード法と同様にクラスタリング手法の1つであるトピックモデルを解説してみたいと思います。
文書・画像・音楽などのデータ集合中の各データを複数のトピックにまたがって分類するためのモデル
若干抽象的な言い回しでイメージが掴みづらいかもしれませんが、基本的にはクラスタリング手法の1つです。ただし、k-means法やウォード法は各データが1つのクラス(データ1はクラスA、データ2はクラスBなど)に所属する前提であるのに対して、トピックモデルは各データが複数のクラス(データ1はクラスAとクラスB、データ2はクラスAとクラスCなど)に所属することを可能にします。
以下でトピックモデルの内容を説明して行きますが、是非この違いを念頭におきながら読み進めていただければと思います。
トピックモデルとは?
説明するまでもないかもしれませんが、そもそも「トピック」というのは「文書や会話におけるテーマや話題」のことです。そのため、トピックモデルは大量の文書などが与えられた時に各文書をトピックごとに分類する(各文書のトピックを推定する)ためのモデルです。ただし、冒頭の定義でも記載したように、必ずしも文書である必要はなく、画像や音楽などでも構いません。画像や音楽にも何かしらのテーマはありますからね。
では、簡単に具体例を見てみましょう。次のような文書を見た時に、あなたはそのトピックは何だと答えますか?
「国会で消費税増税法案が可決されました。」
消費税の話なので、この文書のトピックは「経済」だと考えることができますね。一方で、国会での法案審議の話と捉えることもできるので、この文書のトピックは「政治」だと言っても正しいでしょう。つまり、この文書は「経済」と「政治」の2つのトピックに分類されると結論付けることができます。
この例でご覧いただけたように、トピックと言うのは必ずしも1つに定まるものではなく、1つの文書であっても「経済」と「政治」といったように複数のトピックに分類されることが多々あります。つまり、文書の分類を行なうためのモデルは必然的に複数のトピックにまたがる分類を実行することになります。冒頭でも述べたように、k-means法やウォード法は対象のデータ1つに対して1つのクラスを割り当てることを前提としており、複数クラスを割り当てるという処理には向いていません。その一方で、トピックモデルというのは1つ1つの対象のデータが複数のトピックを持つことを許容するため、文書データのトピック分析に適していると考えられます。
トピックモデルの実際の応用先としては例えば次のようなものが考えられます。
- 多数の顧客のアンケート結果をトピックごとに分類し、アンケート結果分析に活かす。
- ECサイト上の製品のトピック分類を行なう。顧客の過去の購入履歴と類似のトピックに分類される製品をレコメンドする。
潜在的ディリクレ配分法(LDA)
ここまでトピックモデルとは何であるかを説明してきましたが、ここからはトピックモデルの実現手段を簡単に解説してみたいと思います。
トピックモデルの実現手段としてよく知られているのが潜在的ディリクレ配分法(LDA)です。
まず、トピック分析を開始する時点で分析者が持っているデータは次の表のようなものです。縦軸が1つ1つの文書を表しており、横軸が登場する単語の種類です。表中の0または1は文書中に対象の単語が含まれているかどうかを表します。例えば、文書1は単語B,C,Eの欄が1になっているので、文書1はこの3つの単語を含んでいるということになります。これは飽くまで例なので、文書数や単語数が非常に少ないですが、実際のケースでは文書数が数百・数千、単語数が数万などもありえるでしょう。
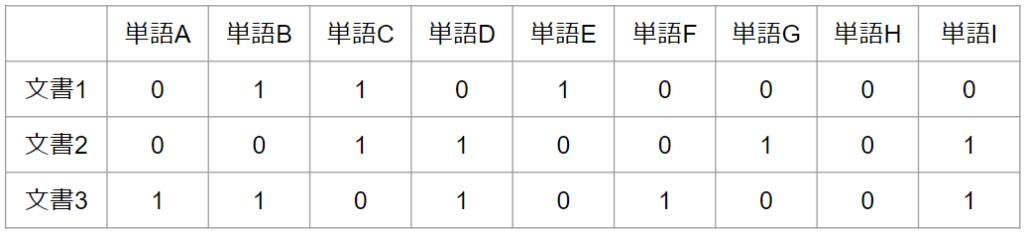
さて、これは手元にある文書群の現状を表現しているわけですが、LDAにおいては、これをある前提のもとで得られた結果だと考えます。ある前提とは次の2つです。
- 各文書を構成するトピックの分布(割合)
- 各トピックに所属する単語の分布(割合)
それぞれの前提の内容を説明します。まず、①は各文書にいろいろなトピックがどのくらいの割合で含まれるのかということなので、図示すると次のようなイメージです。
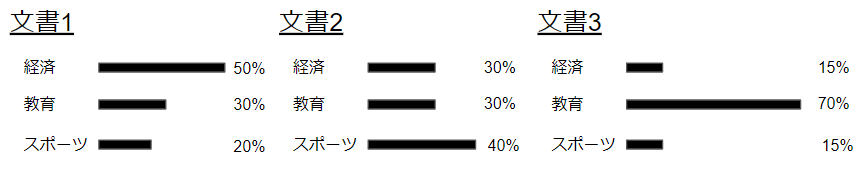
一方で、②は各トピックに所属する単語の分布なので、例えば「経済」というトピックにはどのような単語がどのくらいの割合で出現するのかという指標です。従って、次のような図のイメージで捉えることができます。
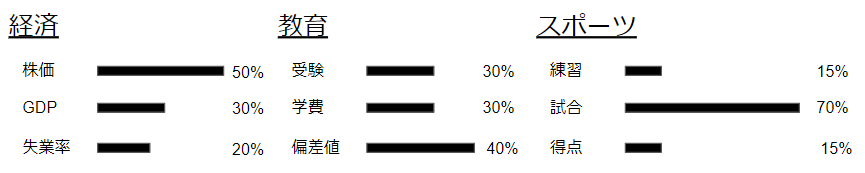
繰り返しになりますが、LDAではこれら2つの前提があり、その結果として各文書にどんな単語が含まれるかが決まるというように考えます。裏を返して言えば、2つの前提は我々が手元に持っている結果が得られやすいような値になっているはずだと考えます(このような考え方を最尤推定と言います)。言ってみれば、結果から前提を逆算するようなものです。もう少し分かりやすい例えで言えば、「100本あるくじのうち10本を引いてみたら当たりが3本だった。ということは、3割が当たりなので、全体で30本の当たりくじがあるはずだ」のように結果から前提を求めるということです。
細かい計算の説明は省略しますが、このような考え方で結果から前提①と②を求めます。そしてもうすでにお気づきだと思いますが、まさに前提①がそもそもトピックモデルで求めることになっていた「各文書のトピックの分類」になっています。なぜなら、文書1の例で言えば経済が主なトピックで、部分的に教育やスポーツの話題も含んでいると解釈できるからです。
これがトピックモデルの具体的手法である潜在的ディリクレ配分法(LDA)の考え方です。
最後に
今回はクラスタリング手法の1つであるトピックモデルを解説してみました。
この記事を通してk-means法やウォード法との違い、応用事例、LDAの基本的な考え方などをご理解していただければ幸いです。
最後になりますが、より詳しく学んでみたいという方は、AIの基礎からAI搭載WEBアプリ開発まで学べるキカガク長期コースも是非活用してみてください!











